Medical file formats
12 Aug 2020#Medical File Formats
- Medical 분야에서 자주 사용되는 Image file format들 정리
-
Pixel depth, photometric interpretation, metadata, pixel data concepts
-
4 Major File Formats
- Analyze, Neuro-imaging Informatics Technology Initiative(Nifti), Minc, Digital Imaging and Communications in Medicine(Dicom)
-
Basic concepts
: Medical Image는 pixels 혹은 voxels로 불리는 신체 내부 구조 이미지 배열로 되어있다. Sampling 혹은 Reconstruction 프로세스를 통해 생성된 이산적인 값들이며, 어떠한 공간에 대한 위치 값들이다. 이러한 값들은 Imaing modality, acquisition protocol, Reconstruction, post-processing 방법들에 의해 영향을 받는다.
-
- Pixel Depth
- 각각 pixel들의 정보들을 인코드 하는데 사용되는 bit 개수이다. pixels image는 12 or 16 bits(컴퓨터는 2bytes를 항상 사용) 을 갖는다.
−32,768 and +32,767 using 15 bits to representthe numbers and 1 bit to represent the sign
-
- Photometric interpretation
- photometric interpretation란 어떻게 올바르게 pixel data를 해석하여 monochrome or color image로 display 할 것인가에 대한 것이다. color information이 저장되어 있는지의 여부를 나타내기 위해 Samples per pixel(a.k.a number of channels)라는 concept을 사용한다.
- Monochrome images(grayscale)은 하나의 채널만을 갖으며 검은색부터 흰색으로 이미지를 표현한다. Clinical radiological images, (e.g x-ray, CT, MR)들은 gray sacle photometric interpretation을 사용한다.
- Nuclear medicine images (e.g positron emission tomography:PET, single photon emission tomography:SPECT)는 일반적으로 color map or color palette를 사용한다. 이러한 경우에는 각각의 픽셀들은 미리 정해진 color map을 사용하는데, display를 위한 것이지, 픽셀 자체에는 저장되지 않는다.
- 그 외에 여전히 one sample per pixel을 갖는 이미지가 있는데 pseudo-color라 불리며 color를 인코드하기 위해 여러 샘플들을 바인딩해서 color를 표현한다.
- Ultrasound Images는 일반적으로 RGB형태로 저장된다. 이러한 경우는 3가지의 primary color들로 결합되어 있는 것이다. 즉 픽셀 당 세가지의 샘플들이 저장된다. Color는 혈액의 흐름을 표현하거나 다른 추가적인 정보들을 표현하기 위해 사용된다. gray scale 이미지에서 혈액을 표현하기 위해 사용되는 fMRI나 PET/CT, PET/MRI 같은 이미지에서 사용된다.

fMRI Image -
- Metadata
- 이미지를 설명하는 정보(the file as a header and contains at least the image matrix dimensions, the spatial resolution, the pixel depth, and the photometric interpretation)로써, medical 이미지에서는 꽤 중요한 역할을 한다. 예를 들어 이미지가 어떻게 생성되었는지, MRI이미지에서는 pulse squence와 관련된 파라미터를 갖는지 또는 timing 정보, flip angle, number of acquistions 등의 정보를 갖는다. 이와 같이 어떠한 진단 방식이 사용됐는지, post-processed는 어떻게 수행되었는지에 대한 powerful한 tool을 제공한다.
-
- Pixel Data
- pixel 값들이 저장되는 부분으로 정수형 혹은 floating-point형으로 값들을 표현한다. fixed-size haeder를 갖는 file들은 header 크기를 skip한 이후의 위치부터 pixel data가 저장된다. 또한 복소수 형태로 저장이 되기도 하는데 자주 사용되지는 않으며, 저장할때도 가수부를 제외한 실수 부분만 저장이 되기도 한다. 이러한 형태는 MRI 이미지에서 Reconstruction 전 단계에서 저장할 때 얻을 수 있다.
\(Pixel Data Size = Rows * Columns * Pixel Depth * Number of Frames\)
\(Image file Size = Header Size + Pixel Data size\)

-
- File Formats
- Medical image file formats은 2가지의 카테고리로 나뉘는데 첫번째는 diagonostic modalities에 의해 만들어진 이미지를 standardize한 것이고(e.g Dicom), 두번째는 post-processing anaylsis를 위해 수정된 타입(e.g Analyze, Nifti, Minc)이다. 또한 이미지들이 저장될 때도 두가지 방식이 있는데, metadata와 image data가 함께 저장되는 것과 나뉘어 저장되는 것이다. 전자는 Dicom, Minc, Nifti가 해당하며 후자는 Analyze이다(.hdr, .img)
-
- Analyze
- 1980년 말에 만들어진것으로 3D or 4D데이터와 같이 multidimensional data(volume)형태로 저장된다. .img, .hdr 확장자로 voxel과 metadata를 따로 저장한다. unsigned 16bit와 같은 basic data types을 포함하지 않아 scale factor 혹은 depth를 직접 바꿔야 한다. 오래되었지만 여전히 널리 사용되며 새로운 format인 AnalyzeAVW가 최신 버전의 소프트웨어에서 사용된다.
-
- Nifti
- 2000년대 초반에 Natonal Institutes of Health 기구에 의해 만들어졌으며 Neuroimaging을 유지보수하기 위해 Analyze format의 장점을 이용하고 단점을 보완시켰다. Analyzer 7.5 Header에 안쓰는 필드에 image orientation이나 left-right ambiguity를 없애는 의도로 보완되었다. header와 pixel data가 따로 저장하게끔도 할 수 있지만 합쳐서 저장하는 .nii 포멧을 지원한다. 이 포멧은 급속하게 Analyze에서 대체되었으며, 가장 널리 퍼진 default format이다. 더 큰 데이터를 처리하기 위해 Nifti-2 Version이 2011년에 만들어졌다.
-
- Minc
- Montreal Neurological Institute (MNI)에서 1992년부터 flexible한 data format을 위해 만들어졌다. 큰 데이터를 처리하가ㅣ 위해 HDF5 형태로 변환하며 이전 것과는 호환되지 않지만 Minc2로 불리며 사용되고 있다.
-
- Dicom
- the American College of Radiology and the National Electric Manufacturers Association에 의해 1993년에 만들어졌지만 90년말부터 실제적으로는 사용되었으며 모든 medical imaging의 backbone이다. Dicom은 파일 format일 뿐만 아니라 network Communications protocol이었다. Dicom의 혁신은 Pixel Data와 Metadata가 분리될 시 의미없는 데이터와 같다고 생각되어 Pixel Data와 Metadata(e.g 환자의 이름, 성, 나이, 체중 등)과 같은 정보들도 포함시켰으며 이는 다양한 사이즈의 데이터를 만들었고, 결국에는 “Phoenix”라는 시스템으로 Dicom image series에서 acquisition window protocol을 이용하여 새로운 정보들을 획득하였다. Dicom은 jpeg와 같은 non-Dicom-formatted 들도 Dicom file에 encapsulate 할 수 있다.
-
-
Discussion
: Dicom같은 경우에는 너무 많은 정보가 들어가있으며 사용하는데 복잡하다는 단점이 있다. 또한 privacy한 정보 또한 포함되어 있다는 점에서 문제가 있다. Nifti는 다양한 data types을 지원하며 적당한 정보가 들어가 있다는점에서 가장 적절한 format인 듯 하다.
reference: Medical image file formats

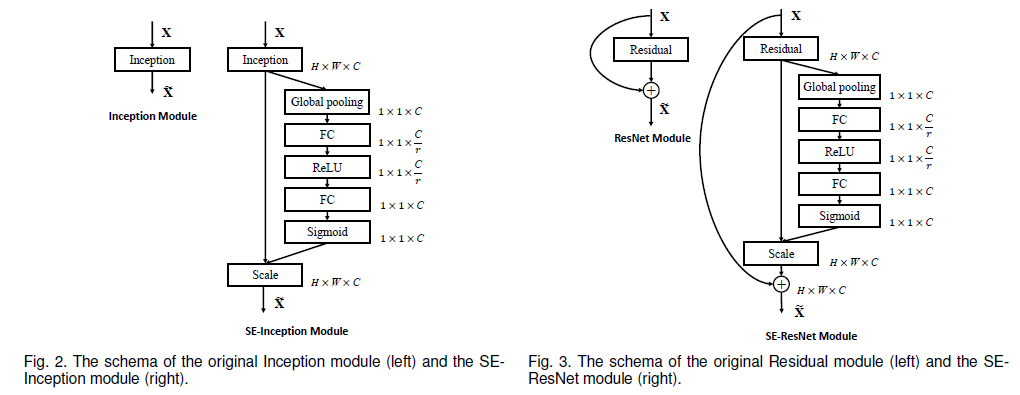
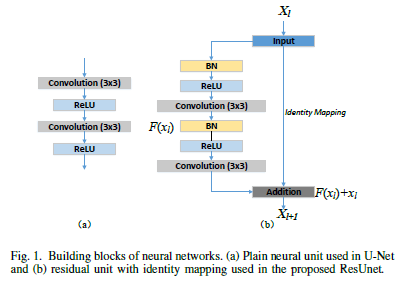
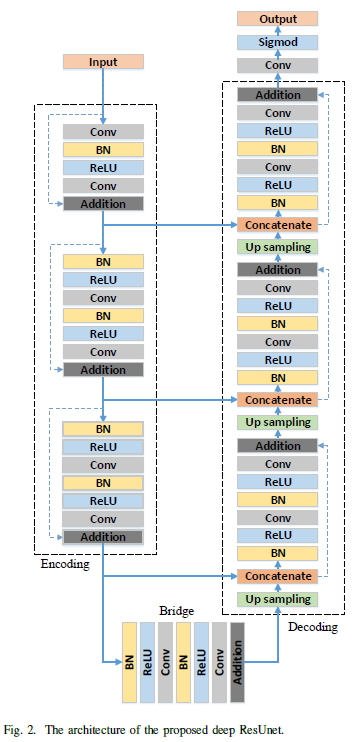
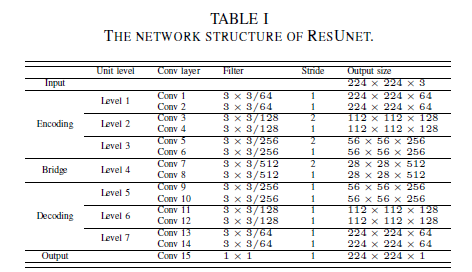
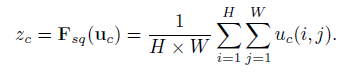 i, j:pixels, H,W: height, width, ${Z_c}$ = output
i, j:pixels, H,W: height, width, ${Z_c}$ = output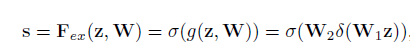 \(\delta=ReLU\)
\(\delta=ReLU\)