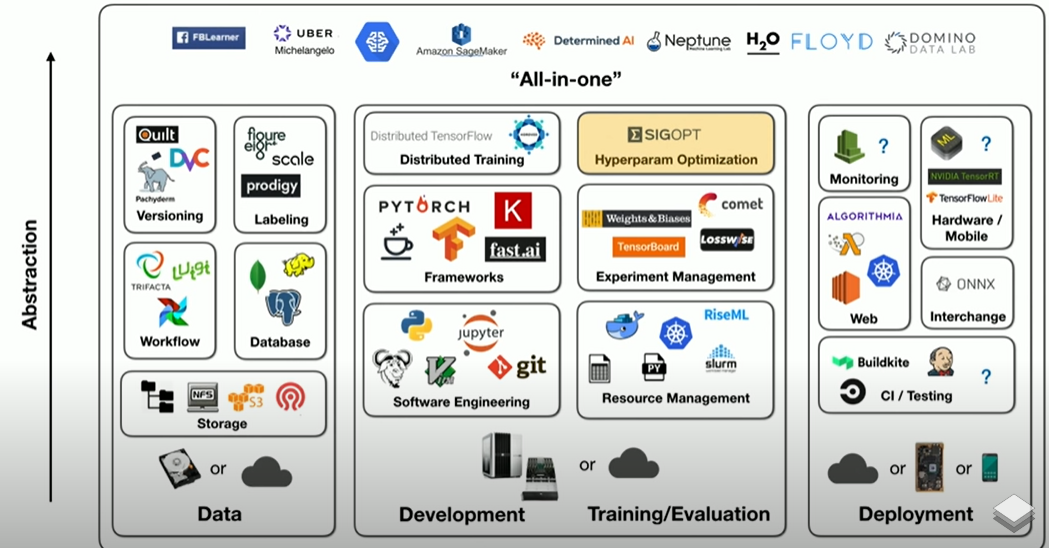
Data augumentation
16 Jul 2020Data Augmentation
개요
- 머신 러닝 시스템을 향상시키기 위해 Data Augmentation을 적용시키는데 좋은 성능을 내는 Model을 찾는 것처럼 Augmentation 또한 좋은 성능을 내는 Augmentation policy를 찾아야 한다. 그런데 좋은 policy를 찾기 위해서는 Domain Knowledge를 필요로 하는데 최근 Data Augmentation policy를 학습하는 방법들이 나타나고 있다. 여기서는 몇 가지 최근에 사용되는 Augmentation 기법을 정리해보고 나아가 좋은 policy를 찾는 방법을 살펴본다
Image Augmentation
-
Horizontal/Vertical Flip, Cropping, Rotate, Scale, Resize, Distortion, ElasticTransform, Shear, Translate-x/y, Sharpness, Contrast, Brightness, Solarize, Identity
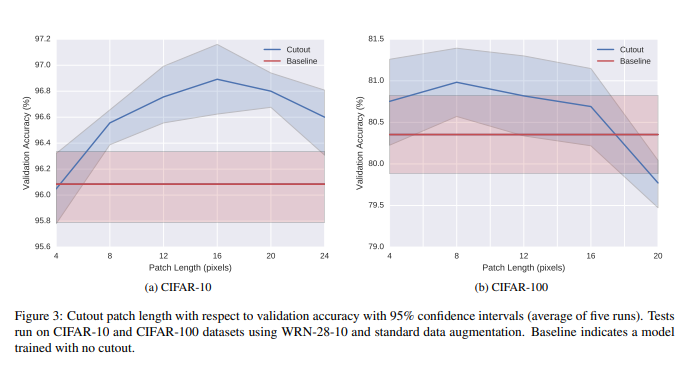
- Cutout
- 입력 이미지 일부분을 가려 모델이 좀 더 이미지의 문맥적인 부분을 학습하게 끔 한다. 가려진 부분보다는 보이는 부분이 더 커야 함
- 가려진 부분의 모양보다는 크기가 더 중요
- Classification에서는 성능이 향상 되었지만 Detection에서는 오히려 성능이 하락
- Cutmix
- 이미지 일부분을 다른 부분으로 대체하여 작은 부분에만의 attention을 다른 global context에도 분산시켜 학습시킨다(ex. 사람의 경우 머리 부분 뿐만 아니라 다리, 팔 등의 부분)
- Cutout같은 경우에는 cropped된 부분의 정보 손실이 있음.
 Cutmix Clovai Github https://github.com/clovaai/CutMix-PyTorch
Cutmix Clovai Github https://github.com/clovaai/CutMix-PyTorch
- Random Augmentation
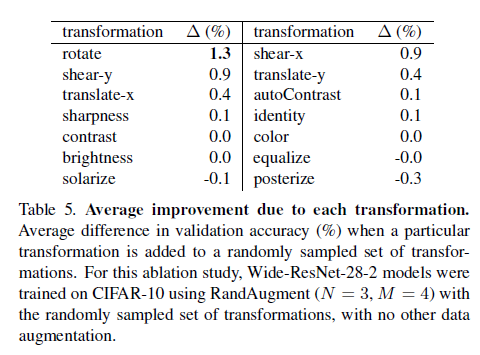
- AA 방식은 search space로 계산 비용이 크므로 search space를 작게만든다.(N*M)
- Search Space를 줄이기 위해 K개의 Transformations을 uniform probability ${1/K}$로 선택, ${K^N}$개의 potential policies 존재
- Transformations N개, Magnitudes M개의 범위의 hyperparameter를 갖는다.
- GridSearch방법을 통해 Parameter를 찾는다.

- Automated Augmentation
- Two Components : Search Algorithm과 Search Space
- Search Algorithm은 Controller RNN으로 구현되어있으며 Data Augmentation Policy S를 생성한다. Policy S에는 어떤 Operation을 사용할지와 Operation을 사용할 확률을 포함한다. Search Algorithm은 Validation accuracy R이 이용된다.
- Policy S는 5개의 Sub-Policy로 나뉘고 각 Sub-policy는 이미지에 적용될 2개의 Operation으로 구성된다. 각각의 Operation은 적용될 확률과 Maginitude로 구성된다.
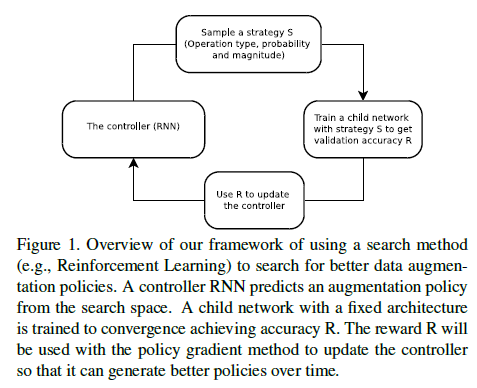
- RNN Controller는 Proximal Policy Optimization(PPO)가 사용된다.