Image Segmentation
28 Jul 2020DeconvNet
- 인코더 디코더 구조, 인코더는 FCN층을 제외한 VGG16 모델을 사용
- Deconvolution Opertation을 사용하여 Upsamling
- Low resolution에서 high resolution으로 변형해가는 디코더 구조에서 Deconvolution operation을 사용

U-Net
- U-shaped models with skip-connections
- Over-tile strategy
- Data augmentation(morphological operation)
- Weight regularization over the distance of cells and borders

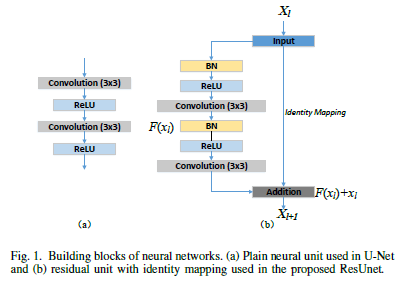
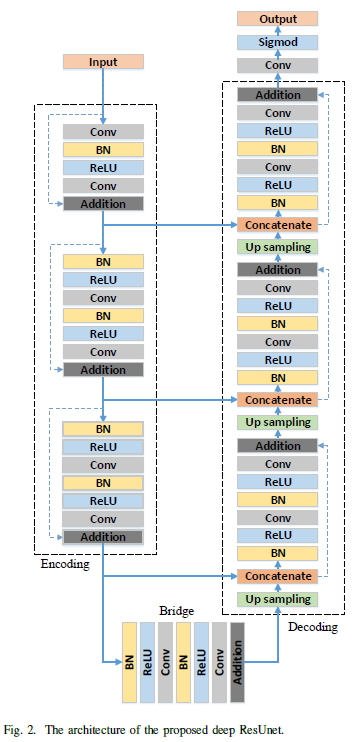
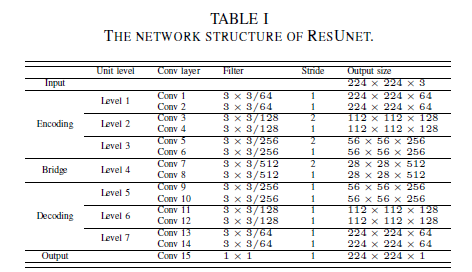
ResUnet
- U-net에서 Low level 쪽으로 갈수록 Detail한 특징을 잡아내지만 High Resolution에 대한 정보를 손실 이에 Residual 방식을 이용하여 backward propagation의 향상과 Low level에서 High level에 이르는 Semeantic 특징을 잘 잡아내도록 함
- U-net 보다 적은 parameter 개수로 better performance
- Pre-activation design을 사용하여 Residual Unit 구현
He et al. presented a detailed discussion on impacts of different combinations in
He. Identity mappings in deep residual networks,” in ECCV, 2016 pp. 630–645.
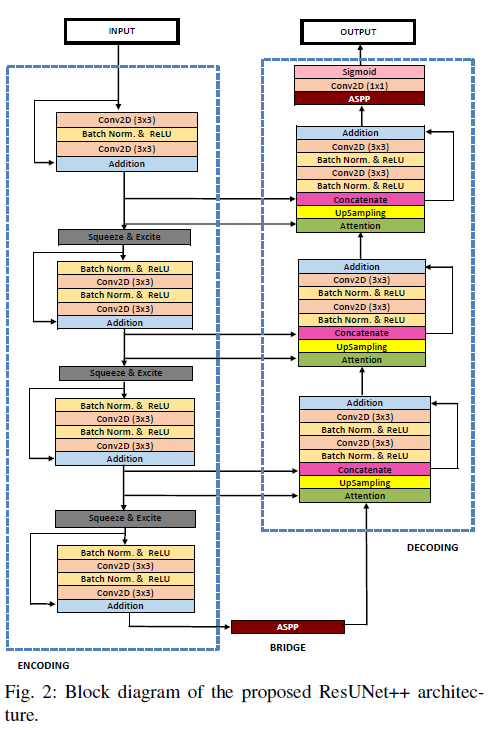
ResUnet++
- ResUnet에서 확장하여 Residual blocks, Squeeze and Excitation Block, ASPP , Attention block 사용
-
- Squeeze and Excitation block
- 모델이 relevant/unnecessary한 features들을 민감하게 만든다. Squeeze는 global average pooling을 통해 channel-wise한 값들을 만들고, Excitation은 channel-wise한 dependencies들을 캡쳐하게 끔한다.
-
- ASPP
- multiple spatial 정보들을 captrue한다. Atrous convoluton은 field of view의 capturing을 정밀하게 끔한다.
-
- Attention
- 이미지에서 more attention 부분에 집중하도록 한다.
DeepLab V3+
-
- Spatial pyramid pooling
- Apply several parallel atrous convolution with different rates(called Atrous Spatial Pyramid Pooling. ASPP)

-
- Atrous convolution
- A powerful tool that allows us to explicitly control the resolution of features computed by deep convolutional neural
networks and adjust filter’s field-of-view in order to capture multi-scale information, generalizes standard convolution operation.

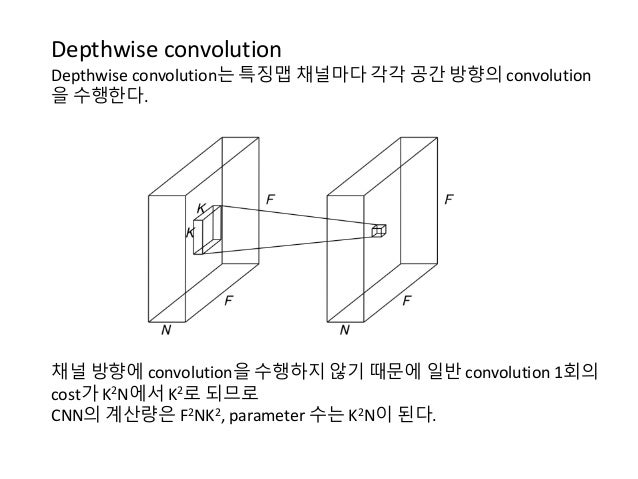
- Depthwise separable convolution
- It reduces computation complexity
- Encoder-Decoder
- Resnet101 / Xeption as Backbone
U-Net++
- U-net모델에서 densely nested 구조로된 skip connection 사용

SegNet
- 인코더 디코더 모델. 인코더는 VGG16 pre trained 모델을 FCN 제외하고 사용
- 인코더 부분에서 Maxpooling indeices라고 해서 맥스풀링 후 사이즈 변화가 없게 0 값을 삽입 후 매번 풀링 값들을 저장하여 디코더에서 Upsamling시 사용
- 인코더에서 저장한 max pooling 값들을 사용하므로 경계 부분이 비교적 선명함.


1) DeconvNet과의 차이점 - Unpooling이라는 유사한 Upsampling 방식이 사용되지만 - SegNet은 FCL이 존재하지 않는다.
2) U-Net과의 차이점 - U-Net은 주로 bio 이미지에서 사용되며 - Pooling Indices를 사용하는 대신 전체 feature map이 encoder에서 decoder로 전송된 다음 연결하여 Convolution을 수행한다. - 이는 모델을 더 크게 만들며 더 많은 메모리 사용을 하게 된다.
ICNN : Interlinked convolutional neural network
- Face Parsing 용도
- Input 이미지를 downsampling(max pooling)을 통해 여러가지 resolution으로 나누어 parallel Network를 만듬

- 64x64 patch를 input으로 눈,코,입,귀 등의 부분으로 나누어 pixel-wise cross-entropy 학습
GridNet : Residual Conv-Deconv Grid Network for Semantic Segmentation
- Grid 형태의 multiple interconnected Network

HRNet: Deep high resolution Representation Learning
- Input image를 4개의 low resolutiond으로 parallel한 network 구성
- low resolution path를 추가 할 때 마다 Densed Skip connection으로 feature map들을 연결
- Final layer에서 수행할 Task에 맞춰 Concatenation 수행


OCR: Object-Contextual Representation for Semantic Segmentation
- 클래스에 속하는 오브젝트와 해당 클리스에 속하는 픽셀을 결합하여 OCR을 생성
1) Pre-trained Model(Resnet)을 사용하여 Supervised learning 방식으로 Object들의 region 정보를 학습(Soft obejct regions)
2) 얻어진 Obejct들에 속하는 pixel로 Pixel Representation 생성

DANet: Dual Attention Network for Scene Segmentation
- A position attention module is proposed to learn the spatial interdependencies of features
- a channel attention module is designed to model channel interdependencies. It significantly improves the segmentation results by modeling rich contextual dependencies over local features
